 New augmented gain.
New augmented gain.
Abstract
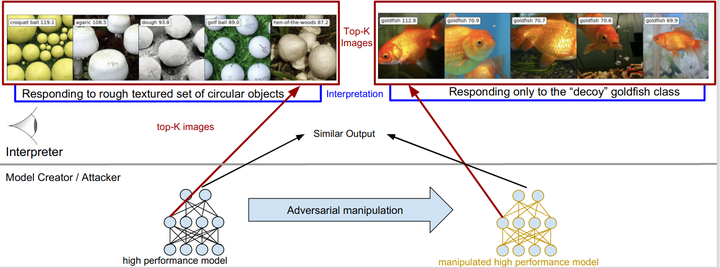
The internal functional behavior of trained Deep Neural Networks is notoriously difficult to interpret. Activation-maximization approaches are one set of techniques used to interpret and analyze trained deep-learning models. These consist in finding inputs that maximally activate a given neuron or feature map. These inputs can be selected from a data set or obtained by optimization. However, interpretability methods may be subject to being deceived. In this work, we consider the concept of an adversary manipulating a model for the purpose of deceiving the interpretation. We propose an optimization framework for performing this manipulation and demonstrate a number of ways that popular activation-maximization interpretation techniques associated with CNNs can be manipulated to change the interpretations, shedding light on the reliability of these methods..
Geraldin Nanfack
Postdoctoral Researcher
My research interests include constraints in machine learning, interpretability and trustworthiness.
