 New augmented gain.
New augmented gain.
Abstract
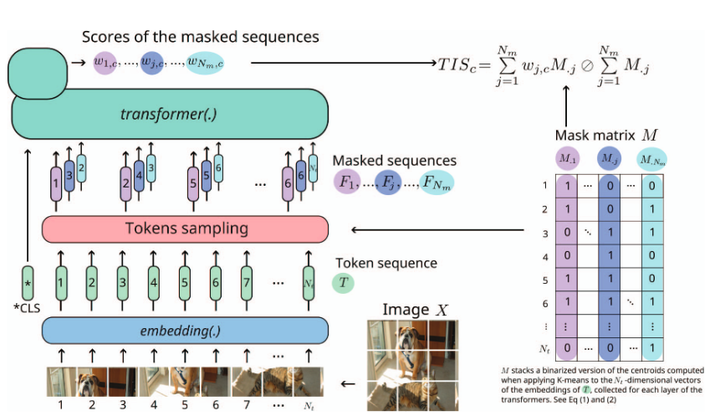
Vision Transformers are becoming more and more the preferred solution to many computer vision problems, which has motivated the development of dedicated explainability methods. Among them, perturbation-based methods offer an elegant way to build saliency maps by analyzing how perturbations of the input image affect the network prediction. However, those methods suffer from the drawback of introducing outlier image features that might mislead the explainability process, e.g. by affecting the output classes independently of the initial image content. To overcome this issue, this paper introduces Transformer Input Sampling (TIS), a perturbation-based explainability method for Vision Transformers, which computes a saliency map based on perturbations induced by a sampling of the input tokens. TIS utilizes the natural property of Transformers which permits a variable input number of tokens, thereby preventing the use of replacement values to generate perturbations. Using standard models such as ViT and DeiT for benchmarking, TIS demonstrates superior performance on several metrics including Insertion, Deletion, and Pointing Game compared to state-of-the-art explainability methods for Transformers. The code for TIS is publicly available at https://github.com/aenglebert/Transformer_Input_Sampling.
Geraldin Nanfack
Postdoctoral Researcher
My research interests include constraints in machine learning, interpretability and trustworthiness.
